Interspeech2026-Audio-Encoder-Challenge
The Interspeech 2026 Audio Encoder Capability Challenge for Large Audio Language Models
🏆 Challenge Results
https://dataoceanai.github.io/Interspeech2026-Audio-Encoder-Challenge/docs/result.html
Overview
The Interspeech 2026 Audio Encoder Capability Challenge, hosted by Xiaomi, University of Surrey, Tsinghua University and Dataocean AI, evaluates pre-trained audio encoders as front-end modules for LALMs, focusing on their ability to understand and represent audio semantics in complex scenarios.
The challenge adopts a unified end-to-end generative evaluation framework. Participants only need to submit a pre-trained encoder model, while the downstream task training and evaluation are completed by the organizers. The organizers provide XARES-LLM benchmark, an open-source evaluation system. XARES-LLM trains a typical LALM using the audio encoder provided by the user. The system automatically downloads training data, trains the LALM then tests various downstream tasks, providing scores for each. The XARES-LLM system is depicted in Figure below.
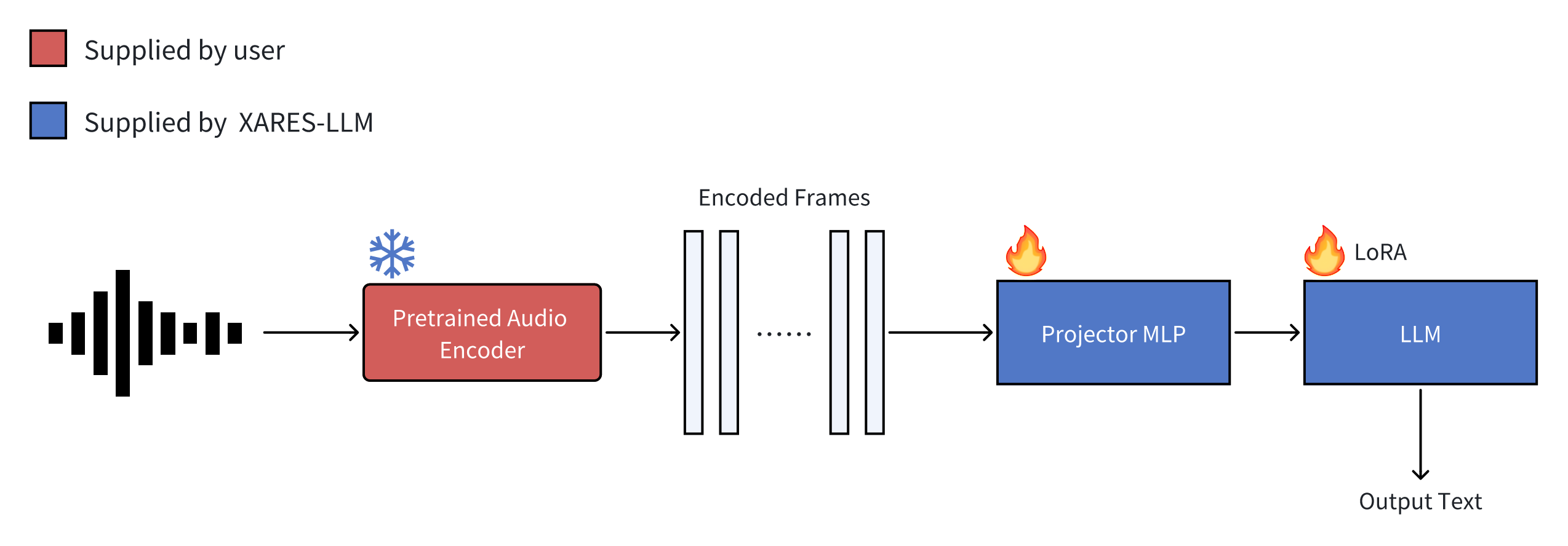
The only mandatory task for all participants is to encapsulate their encoder according to the framework requirements properly.
Training is done by jointly training on all datasets using a predefined mixture, by balancing each task respectively. All datasets have been organized into the WebDataset format and uploaded to HuggingFace and will be downloaded automatically during runtime. Users are not allowed to change the content or proportion of the training set. To encourage broad participation, commercial-grade datasets are provided free of charge to all registered teams with non-business use license.
Participants are welcome to independently test and refine their models, but the final rankings will be determined based on evaluations performed by the organizers.
Track Setup
Track A: Classification tasks
The preprocessed datasets are available on Hugging Face. The number of labels # for each dataset is displayed.
| Domain | Dataset | Task Type | Metric | # |
|---|---|---|---|---|
| Speech | Speech Commands | Keyword spotting | Acc | 30 |
| LibriCount | Speaker counting | Acc | 11 | |
| VoxLingua33 | Language identification | Acc | 33 | |
| VoxCeleb1-Binary | Binary speaker identification | Acc | 2 | |
| ASVspoof2015 | Spoofing detection | Acc | 2 | |
| Fluent Speech Commands | Intent classification | Acc | 31 | |
| VocalSound | Non-speech sounds | Acc | 6 | |
| CREMA-D | Emotion recognition | Acc | 5 | |
| Sound | ESC-50 | Environment classification | Acc | 50 |
| FSD50k | Sound event detection | mAP | 200 | |
| UrbanSound 8k | Urban sound classification | Acc | 10 | |
| FSD18-Kaggle | Sound event detection | mAP | 41 | |
| Music | GTZAN Genre | Genre classification | Acc | 10 |
| NSynth-Instruments | Instruments Classification | Acc | 11 | |
| Free Music Archive Small | Music genre classification | Acc | 8 |
Track B: Understanding tasks
The preprocessed datasets are available on Hugging Face.
| Dataset | Task Type | Metric |
|---|---|---|
| LibriSpeech-100h | Speech recognition | iWER |
| AISHELL-1-100h | Speech recognition | iWER |
| Clotho | Sound Caption | FENSE |
| The Song Describer Dataset | Music Caption | FENSE |
| MECAT | General Caption | DATE |
Training Datasets
The challenge places a significant emphasis on data collection and utilization, which is a crucial component of the competition. The organizers do not prescribe a specific training dataset for each participant. Instead, participants are free to use any data for training, as long as it meets the following conditions:
- All training data must be publicly accessible, or in 20-Hour Non-speech Dataset from DataoceanAI.
- Any use of publicly available data must be clearly and comprehensively documented in the technical report paper, including data composition and proportions. Submissions that fail to meet this requirement will be considered invalid.
Evaluation and Ranking
Performance is evaluated separately for Track A and Track B.
For each track, its raw score is converted into a normalized score between 0 and 1 using a linear mapping method. This process proportionally scales the raw score so that 0 corresponds to the worst possible outcome and 1 to the best possible outcome for that specific task.
The final result for each track is the simple average of the normalized scores. The two scores are calculated and reported individually, without being combined into an overall average.
Note that we strongly encourage participants to focus on developing general-purpose audio representations rather than over-optimizing for XARES-LLM, as the final ranking will also incorporate results from hidden test datasets.
How to Participate
Registration
To participate, registration is required. Please complete the registration form before January 15, 2026.
Further questions, please send Email to: 2026interspeech-aecc@dataoceanai.com
Submission Rule
Participants are required to submit a pre-trained model encapsulated within the specified API. The model should accept a single-channel audio signal, represented as a PyTorch tensor with shape [B, T], and an optional mask of shape [B,T] where B denotes the batch size and T represents the number of samples in the time domain and ones represent keep in the mask, while zero represent discard. The model should output a frame-level prediction of shape [B, T′,D], where T′ can be different from the input T and D is the embedding dimension defined by the participant as well as the optional mask of shape [B, T’].
While there are no strict limitations on model size, submitted models must be able to be run successfully on a card with 24G RAM.
Each team may submit only one model, and each individual may belong to only one team.
The submission steps are as follows:
-
Clone the audio encoder template from the GitHub repository.
-
Implement your own audio encoder following the instructions in
README.mdwithin the cloned repository. The implementation must pass all checks inaudio_encoder_checker.pyprovided in the repository. -
Before the submission deadline, email the organizers a ZIP file containing the complete repository. Additionally, please attach a technical report paper (PDF format) not exceeding 6 pages describing your implementation. Pre-trained model weights can either be included in the ZIP file or downloaded automatically from external sources (e.g., Hugging Face) during runtime. If choosing the latter approach, please implement the automatic downloading mechanism in your encoder implementation.
Participants are also required to submit a technical report along with their submission. The technical report should clearly document the training data and their proportions, which is required for the submission to be eligible for the ranking.
Important Dates
-
December 15, 2025: Challenge announcement
-
February 12 23:59 AoE, 2026: Submissions Deadline
-
February 20March 9, 2026: Final Ranking Announced -
February 25 23:59 AoE, 2026: Paper Submission Deadline
Citation
@misc{dinkel2026interspeech2026audioencoder,
title={The Interspeech 2026 Audio Encoder Capability Challenge for Large Audio Language Models},
author={Heinrich Dinkel and Jiahao Zhou and Guanbo Wang and Yadong Niu and Junbo Zhang and Yufeng Hao and Ying Liu and Ke Li and Wenwu Wang and Zhiyong Wu and Jian Luan},
year={2026},
eprint={2603.22728},
archivePrefix={arXiv},
primaryClass={cs.SD},
url={https://arxiv.org/abs/2603.22728},
}